Conteúdo
- 1 IDENTIFICANDO FRAUDES NO CARTÃO DE CRÉDITO
- 2 MACHINE LEARNING
Conteúdo
Por Hyan Dias Tavares • JAN 31, 2022
MACHINE LEARNING
CARTÃO CREDITO
FRAUDE
PCA

A um surgimento exponencial de novos métodos de pagamentos, que vem movimentando o mercado financeiro (pix, carteira digital e Qr code), mas apesar dessas mudanças, o cartão de crédito ainda continua sendo um dos preferidos dos brasileiros, movimentando em 2021 50 Bilhões de transações, segundo a BC.
Esse cenário faz com que sejam atraídos bandidos e quadrilhas que usam o sistema para fraudar. Roubam os dados de clientes, se passando pelo mesmo e assim fazendo transações ilegais. Apenas no Brasil, cerca de 12,1 milhões de pessoas já foram vítimas de algum tipo de fraude financeira no último ano. Traduzindo em valores, os golpes financeiros ultrapassaram a cifra de R$ 1,8 bilhão de prejuízo por ano para os últimos 12 meses.
É uma dor de cabeça para os clientes e bancos, assim começa a corrida em busca de métodos para detectar essas transações e impedir assim que aconteça.
Nesse artigo, vamos utilizar um algoritmo baseado em Machine Learning (máquina de aprendizado) para detectar as fraudes.
“Machine Learning é uma tecnologia onde os computadores têm a capacidade de aprender de acordo com as respostas esperadas por meio associações de diferentes dados, os quais podem ser imagens, números e tudo que essa tecnologia possa identificar”.
Esse mecanismo funciona de muitas maneiras, mas segue um conceito base, na qual serve como um roteiro no momento de desenvolver o algoritmo.
Os dados que usaremos neste projeto foram disponibilizados por algumas empresas europeias de cartão de crédito. O dataset representa as operações financeiras que aconteceram no período de três dias, onde foram classificadas 492 fraudes em meio a quase 280 mil transações.
Como você pode notar, este é um conjunto de dados extremamente desbalanceado, onde as fraudes representam apenas 0,17% do total.
Ele contém apenas variáveis de entrada numéricas que são o resultado de uma transformação PCA (Principal Component Analysis). Infelizmente, devido a questões de confidencialidade, a instituição que fornece os dados não podem fornecer os recursos originais e mais informações básicas sobre os dados.
As variáveis V1, V2, … V28 são os principais componentes obtidos com PCA, as únicas características que não foram transformadas com PCA são ‘Time‘ and ‘Amount‘.
Atenção: O portal está em constante mudança, e existe a possibilidade do conjunto de dados utilizados ser atualizado ou removido, não estando mais disponível, o que poderá trazer erros no código.
E para resolver isso, disponibilizei o arquivo Credicard, diretamente do meu Dropbox, para poder replicar esse processo em outros momentos.
Vamos importar todos os pacotes e módulos que iremos utilizar. Borá abrir sua IDE ou o google colab.
In [1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
!pip install -q scikit-plot
import scikitplot as skplt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.metrics import precision_recall_curve, average_precision_score, confusion_matrix, auc, roc_curve
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score, accuracy_score, classification_report
A principal biblioteca que vamos importar para construir nossa Machine Learning se chama scikit-lear, que possui diversos métodos, algoritmos e técnicas bem interessantes que simplificam a vida.
Vamos importar os arquivos credcard.csv para os dataframe df.
In [2]:
df = pd.read_csv("https://www.dropbox.com/s/ztwen3072mzwgvf/creditcard.csv?dl=1")
Uma dica para quem usar o Dropbox, quando você gera um link para compartilhar o seu Dataset (csv), note que no final do link vai haver o código dl=0, altere ele para dl=1, assim você irá informar ao Dropbox que queremos o arquivo Excel e não o HTML.
Já citamos anteriormente quais variáveis iremos encontrar, que decorrente a transformação feita usando PCA, iremos ter colunas V1, V2, … V28, variáveis transformadas e o Amount, Time e Class que permanecerão inalteradas.
Vamos investigar os dados do dataframe e analisar as 5 primeiras entradas.
In [3]:
df.head()Out [3]:
New York
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | -0.551600 | -0.617801 | -0.991390 | -0.311169 | 1.468177 | -0.470401 | 0.207971 | 0.025791 | 0.403993 | 0.251412 | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | 1.612727 | 1.065235 | 0.489095 | -0.143772 | 0.635558 | 0.463917 | -0.114805 | -0.183361 | -0.145783 | -0.069083 | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1514654 | 0.207643 | 0.624501 | 0.066084 | 0.717293 | -0.165946 | 2.345865 | -2890083 | 1.109969 | -0.121359 | -2261857 | 0.524980 | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1387024 | -0.054952 | -0.226487 | 0.178228 | 0.507757 | -0.287924 | -0.631418 | -1.059647 | -0.684093 | 1.965775 | -1.232622 | -0.208038 | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | -0.822843 | 0.538196 | 1.345852 | -1.119670 | 0.175121 | -0.451449 | -0.237033 | -0.038195 | 0.803487 | 0.408542 | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
O próprio site detentor do dataset, já nos diz haver 280 mil transações e que as fraudes correspondem a 0,17%. E para ter certeza vamos fazer uma análise profunda.
In [4]:
print(f'Entradas: {df.shape[0]}\nVariáveis: {df.shape[1]}\n')
Out [4]:
Entradas: 284807
Variáveis: 31
Investigando o volume de dados, identificamos que temos 284.807 entradas (transações) e 31 variáveis no total.
Os atributos dos dados ou tipos primitivos, são os formatos dos dados em que a linguagem (python) irá interpretar. E para examinarmos os atributos das nossas variáveis bastas digitar.
In [5]:
df.dtypesOut [5]:
Time float64
V1 float64
V2 float64
V3 float64
V4 float64
V5 float64
V6 float64
V7 float64
V8 float64
V9 float64
V10 float64
V11 float64
V12 float64
V13 float64
V14 float64
V15 float64
V16 float64
V17 float64
V12 float64
V18 float64
V19 float64
V20 float64
V21 float64
V22 float64
V23 float64
V24 float64
V25 float64
V26 float64
V27 float64
V28 float64
Amount float64
Class intt64
dtype: object
Todos os tipos são float, ou seja, números reais, com exceção da variável Class que é um número inteiro. Vamos aproveitar e identificar se há valores ausentes.
In [6]:
df.isnull().sum() / df.shape[0]
Out [6]:
Time 0.0
V1 0.0
V2 0.0
V3 0.0
V4 0.0
V5 0.0
V6 0.0
V7 0.0
V8 0.0
V9 0.0
V10 0.0
V11 0.0
V12 0.0
V13 0.0
V14 0.0
V15 0.0
V16 0.0
V17 0.0
V12 0.0
V18 0.0
V19 0.0
V20 0.0
V21 0.0
V22 0.0
V23 0.0
V24 0.0
V25 0.0
V26 0.0
V27 0.0
V28 0.0
Amount 0.0
Class 0.0
dtype: object
Como é possível perceber, não temos nenhum valor ausente, facilitando nossa vida em relação ao tratamento desses dados. Não podemos esquecer de observar a distribuição das nossas variáveis e se há outliers. Para isso vamos explorar um pouco os parâmetros estatísticos.
In [7]:
df.describe()Out [7]:
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 | 2.848070e+5 |
| mean | 94813.859575 | 3.91956E-9 | 5.688174E-10 | -8.769071E-9 | 2.782312E-9 | -1.552563E-9 | 2.010663E-9 | -1.694249E-9 | -1.927028E-10 | -3.137024E-9 | 1.768627E-9 | 9.170318E-10 | -1.810658E-9 | 1.693438E-9 | 1.479045E-9 | 3.482336E-9 | 1.392007E-9 | -7.528491E-10 | 4.328772E-10 | 9.049732E-10 | 5.085503E-10 | 1.537294E-10 | 7.959909E-10 | 5.36759E-10 | 4.458112E-9 | 1.453003E-9 | 1.699104E-9 | -3.660161E-10 | -1.206049E-10 | 88.349619 | 0.001727 |
| std | 47488.145955 | 1958696 | 1651309 | 1516255 | 1415869 | 1380247 | 1332271 | 1237094 | 1194353 | 1098632 | 1088850 | 1020713 | 999201.4 | 995274.2 | 958595.6 | 915316 | 876252.9 | 849337.1 | 838176.2 | 814040.5 | 770925 | 734524 | 725701.6 | 624460.3 | 605647.1 | 521278.1 | 482227 | 403632.5 | 330083.3 | 250.120109 | 0.041527 |
| min | 0.000000 | -56407510 | -72715730 | -48325590 | -5683171 | -113743300 | -26160510 | -43557240 | -73216720 | -13434070 | -24588260 | -4797473 | -18683710 | -5791881 | -19214330 | -4498945 | -14129850 | -25162800 | -9498746 | -7213527 | -54497720 | -34830380 | -10933140 | -44807740 | -2836627 | -10295400 | -2604551 | -22565680 | -15430080 | 0.000000 | 0.000000 |
| 0.25 | 54201.500000 | -920373.4 | -598549.9 | -890364.8 | -848640.1 | -691597.1 | -768295.6 | -554075.9 | -208629.7 | -643097.6 | -535425.7 | -762494.2 | -405571.5 | -648539.3 | -425574 | -582884.3 | -468036.8 | -483748.3 | -498849.8 | -456298.9 | -211721.4 | -228394.9 | -542350.4 | -161846.3 | -354586.1 | -317145.1 | -326983.9 | -70839.53 | -52959.79 | 5.600000 | 0.000000 |
| 0.5 | 84692.000000 | 18108.8 | 65485.56 | 179846.3 | -19846.53 | -54335.83 | -274187.1 | 40103.08 | 22358.04 | -51428.73 | -92917.38 | -32757.35 | 140032.6 | -13568.06 | 50601.32 | 48071.55 | 66413.32 | -65675.75 | -3636.312 | 3734.823 | -62481.09 | -29450.17 | 6781.943 | -11192.93 | 40976.06 | 16593.5 | -52139.11 | 1342.146 | 11243.83 | 22.000000 | 0.000000 |
| 0.75 | 139320.500000 | 1315642 | 803723.9 | 1027196 | 743341.3 | 611926.4 | 398564.9 | 570436.1 | 327345.9 | 597139 | 453923.4 | 739593.4 | 618238 | 662505 | 493149.8 | 648820.8 | 523296.3 | 399675 | 500806.7 | 458949.4 | 133040.8 | 186377.2 | 528553.6 | 147642.1 | 439526.6 | 350715.6 | 240952.2 | 91045.12 | 78279.95 | 77.165000 | 0.000000 |
| max | 172792.000000 | 2454930 | 22057730 | 9382558 | 16875340 | 34801670 | 73301630 | 120589500 | 20007210 | 15594990 | 23745140 | 12018910 | 7848392 | 7126883 | 10526770 | 8877742 | 17315110 | 9253526 | 5041069 | 5591971 | 39420900 | 27202840 | 10503090 | 22528410 | 4584549 | 7519589 | 3517346 | 31612200 | 33847810 | 25691.160000 | 1.000000 |
As variáveis transformadas pelo PCA, não tiveram um grande desvio padrão, ou seja, variância entre os pontos.
Já a variável Amout, possui um desvio padrão de 250, isso se dá por haver alguns pontos discrepantes, tendo um ponto máximo de ~$ 25 mil, entretanto, sua média e mediana correspondeu respectivamente $ 88,00 e 22,00, uma diferença bem grande.
E para entender melhor essa distribuição, vamos ver quantas transações são fraudes e quantas são legítimas. Só lembrando que:
0 – Transação normal
1 – Fraude
In [8]:
print(f'N° Fraude: {df[df.Class == 1].value_counts().sum()} ({(df[df.Class == 1].shape[0] / df.shape[0]) * 100:.3f}%)')
print(f'N° Normal: {df[df.Class == 0].value_counts().sum()} ({(df[df.Class == 0].shape[0] / df.shape[0]) * 100:.3f}%)\n')
fig, ax = plt.subplots()
sns.countplot('Class', data=df, color='#9b59b6')
sns.despine(left=True)
ax.set_title('Distribuição das Classes')
ax.set_facecolor('White')
plt.plot()
Out [8]:
N° Fraude: 492 (0.173%)
N° Normal: 284315 (99.827%)
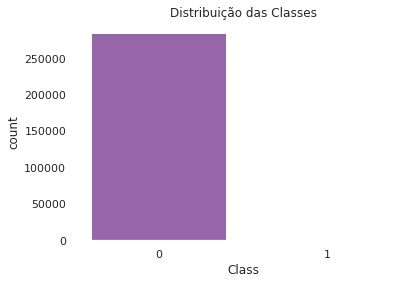
Há uma diferença muito grande em quantidade de transações normais para fraudes, isso vai impactar quando estivermos desenvolvendo nosso modelo de Machine Learning, requerendo mais tarde balancear essa proporção.
Outro ponto a observar é a distribuição da quantidade de transações por tempo e comparar se há um padrão entre o normal e as fraudes.
In [9]:
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(12,6))
plt.subplots_adjust(left=0.125, bottom=0.1, right=0.9, top=0.9, wspace=0.2, hspace=0.35)
num_bins = 40
ax[0].hist(df.Time[df.Class == 0], bins=num_bins, color = "#9b59b6")
ax[0].set_title('Normal')
ax[0].set_facecolor('White')
ax[1].hist(df.Time[df.Class == 1], bins=num_bins, color = "silver")
ax[1].set_title('Fraude')
ax[1].set_facecolor('White')
plt.xlabel('Tempo')
plt.ylabel('Transações')
Out [9]:
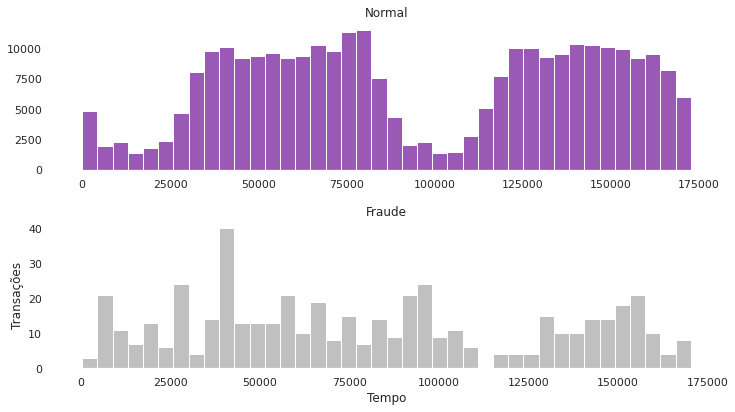
Ambas às duas possuem um padrão sazonal, daria até em um tópico futuro fazer uma análise de séries temporais, mas para o momento isso basta. Além disso, não conseguimos tirar muitas informações relevantes.
Vamos observar a distribuição do Amount, nesse caso usaremos o boxblot como método de análise para distribuição e identificação de outliers.
In [10]:
ax, fig = plt.subplots(figsize=(16,9))
c = "purple"
box = plt.boxplot([df.Amount[df.Class == 1], df.Amount[df.Class == 0]], labels=['Fraude', 'Normal'], vert=False, patch_artist=True)
plt.xlim((-20, 400))
fig.set_facecolor('White')
colors = ['silver', '#9b59b6']
for patch, color in zip(box['boxes'], colors):
patch.set_facecolor(color)
Out [10]:
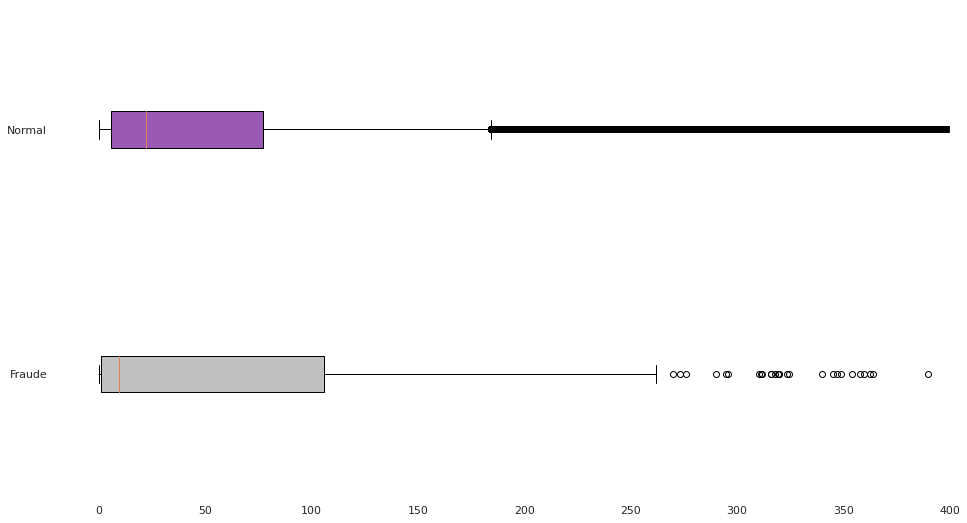
As transações normais possuem muito mais pontos discrepantes, e outro fato é que possui uma mediana maior que as transações fraudulentas. Ou seja, os bandidos tentam atacar usando valores baixos para não serem pegos.
Já que analisamos as variáveis mais importantes, vamos dar uma olhada naquelas que houve a transformação PCA e ver se há uma semelhança na distribuição entre fraude e normal, usando uma função de densidade de probabilidade contínua (kdeplot).
In [11]:
dx = ['V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9', 'V10', 'V11',
'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19', 'V20', 'V21',
'V22', 'V23', 'V24', 'V25', 'V26', 'V27', 'V28']
class_0 = df[df.Class == 0]
class_1 = df[df.Class == 1]
fig, ax = plt.subplots(nrows=7, ncols=4, figsize=(18,18))
fig.subplots_adjust(hspace=0.5, wspace=0.2)
i = 0
for n in dx:
i += 1
plt.subplot(7, 4, i)
sns.kdeplot(class_0[n], label='Normal', shade=True, color='purple')
sns.kdeplot(class_1[n], label='Fraude', shade=True, color='gray')
plt.legend(loc='upper left')
Out [11]:
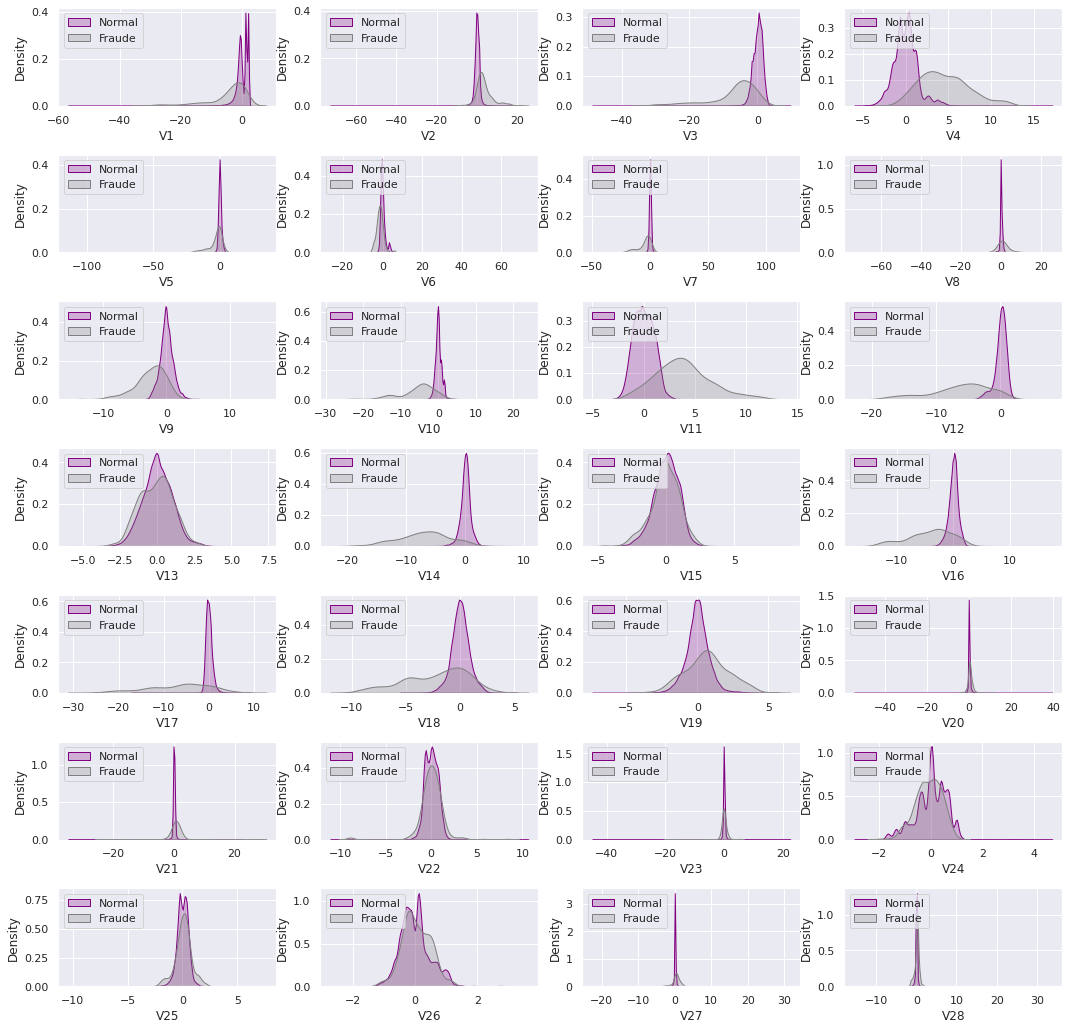
As variáveis V13, 15, 22, 24, 25, 26 e 28, são muito semelhantes, isso pode ser um prelúdio, que serão variáveis que não terão um grau de importância para a detecção de fraudes, sendo elas difícil de distinguir ou separar o que é fraude do que não é. Mas claro, isso é só uma hipótese, temos que observar na prática.
Enfim chegamos a um momento crítico e importante, padronizar os dados é uma etapa importantíssima que consiste na transformação dos dados, é uma prática para evitar que seu algoritmo fique enviesado para as variáveis com maior ordem de grandeza.
É um método que tem o objetivo de transformar todas as variáveis na mesma ordem de grandeza, resultando em uma média igual a 0 e um desvio padrão igual a 1. Usaremos o código StandardScaler()
Matematicamente falando o código StandardScaler() usa a fórmula z-score para fazer a padronização dos dados:
z=\frac{x-\mu}{\sigma}
Vamos fazer uma cópia do dataframa, padronizar as colunas Amount e times, por fim vamos mostrar os dados transformados.
In [12]:
# Copia do dataframe
df_clean = df.copy()
# Padronizar as colunas Time e Amount
scaler = StandardScaler()
df_clean['Amount'] = scaler.fit_transform(df_clean['Amount'].values.reshape(-1,1))
df_clean['Time'] = scaler.fit_transform(df_clean['Time'].values.reshape(-1, 1))
#ver as 5 primeiras linhas
df_clean.head()
Out [12]:
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | V12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.996583 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | -0.551600 | -0.617801 | -0.991390 | -0.311169 | 1.468177 | -0.470401 | 0.207971 | 0.025791 | 0.403993 | 0.251412 | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 0.244964 | 0 |
| 1 | -1.996583 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | 1.612727 | 1.065235 | 0.489095 | -0.143772 | 0.635558 | 0.463917 | -0.114805 | -0.183361 | -0.145783 | -0.069083 | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | -0.342475 | 0 |
| 2 | -1.996562 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | 0.624501 | 0.066084 | 0.717293 | -0.165946 | 2.345865 | -2890083 | 1.109969 | -0.121359 | -2261857 | 0.524980 | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 1.160686 | 0 |
| 3 | -1.996562 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | -0.226487 | 0.178228 | 0.507757 | -0.287924 | -0.631418 | -1.059647 | -0.684093 | 1.965775 | -1232622 | -0.208038 | -0.108300 | 0.005274 | -0.190321 | -1175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 0.140534 | 0 |
| 4 | -1.996541 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | -0.822843 | 0.538196 | 1.345852 | -1119670 | 0.175121 | -0.451449 | -0.237033 | -0.038195 | 0.803487 | 0.408542 | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | -0.073403 | 0 |
É uma convenção separar uma quantidade de dados do dataframe para treinar o modelo de Machine Learning e com outra parte usar para testá-la, ou seja, ver se irá atingir um bom desempenho na verificação de fraudes
Os dados de treino representam cerca de 70% da totalidade, enquanto os dados de teste representam 30%. Para fazermos isso vamos separar o dataframe em dois:
X – Corresponde a todas as variáveis (Amount, time, V1 à V28)
y – Corresponde a resposta (Class).
O passo seguinte é usar a função train_test_split que irá separar dados em treino e teste correspondendo respectivamente as variáveis independentes (X_train, X_test) e variáveis dependentes (y_train, y_test).
In [13]:
X = df_clean.drop('Class', axis=1)
y = df_clean.Class
#separar treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y)
Escolher o modelo de Machine Learning é uma ciência, onde é possível haver vários resultados diferentes dependendo do modelo escolhido. Para meios de simplificação do nosso estudo, vamos utilizar a regressão logística, por entender que o problema proposto é uma solução binária 0 ou 1, caso esse característico da regressão logística, mas abro aspas “árvore de decisão e kmeans são modelos que poderiam ser utilizados no estudo e podem ser até mais eficientes que a regressão logística“, se tornando esse, um fator a mais quando pensamos em comparar modelos de treino.
A Regressão Logística é um algoritmo de Aprendizado de Máquina utilizado para a classificação de problemas, é um algoritmo de análise preditiva e baseado no conceito de probabilidade.
Alguns dos exemplos de problemas de classificação são spam de e-mail ou não spam, transações online fraude ou não fraude, tumor maligno ou benigno. A regressão logística transforma sua saída usando a função sigmóide logística para retornar um valor de probabilidade.
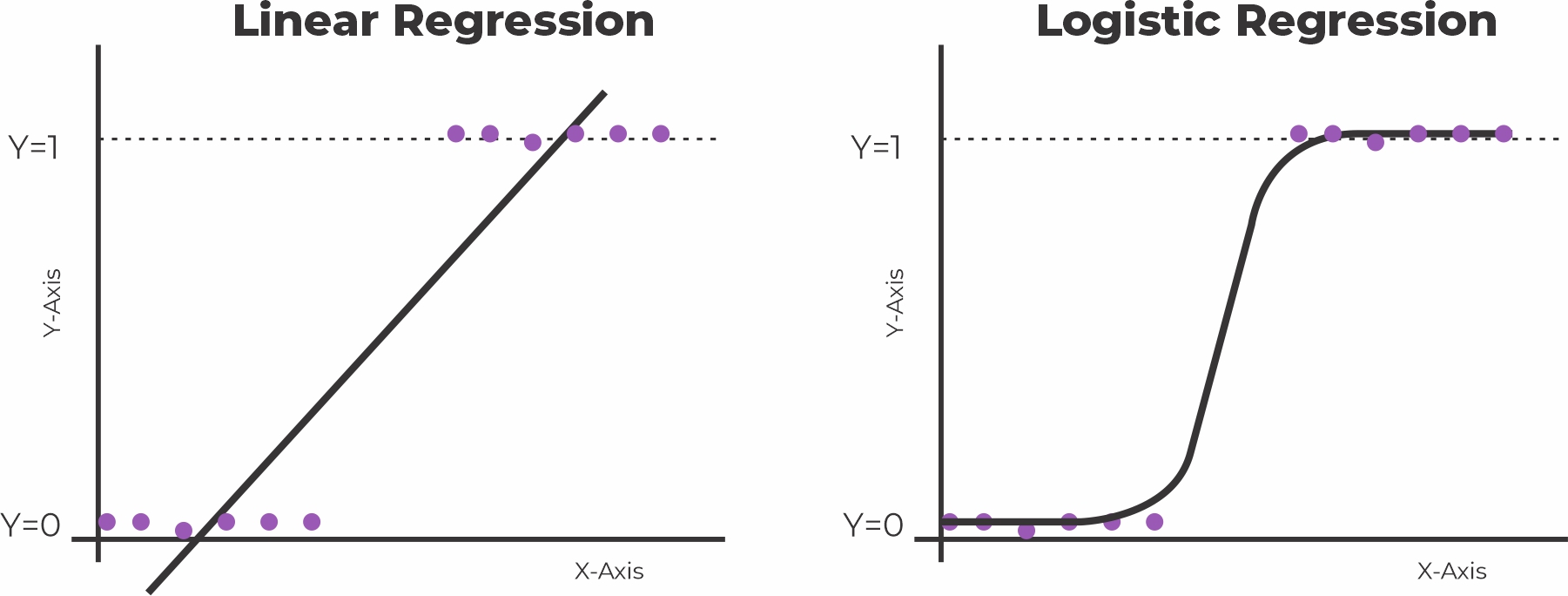
Usaremos a função LogisticRegression() para treinar o modelo, mas antes disso, mostrarei o conceito matemático por trás do código.
E esta função vai ser usada para estimar a probabilidade da classe. Ou seja, vou calcular a probabilidade de y ser igual a zero para os dados que observei os atributos (X). O mesmo acontecerá para avaliar a probabilidade de y ser igual a 1.
p\left (y=0|X \right) e p\left (y=1|X \right)
Vamos usar equação logística ou também conhecida como curva sigmóide, pois nessa característica dos pontos, é ela que se encaixa melhor, conforme é observado na imagem acima.
Função sigmóide ou logística
f\left ( z \right )=\frac{1}{1+e^{-z}}
Temos que também relembrar e trazer os elementos da regressão linear para podermos calcular, já que este método utiliza de coeficientes para ajustar a curva:
\widehat{y}=z=\theta ^{T}X
Vamos calcular as probabilidades substituindo o z na curva sigmoide para ambas as probabilidades:
p\left ( y=1|X \right ) p = \frac{1}{1+e^{-\theta ^{T}X}}
p\left ( y=0|X \right ) 1-p =1- \frac{1}{1+e^{-\theta ^{T}X}}
Para irmos a próxima etapa, precisamos evocar a distribuição de Bernoulli, aplicada em casos de experimentos repetidos, onde existem dois possíveis resultados [0 e 1]. Ela nos fornecerá os termo matemáticos para cada umas das hipóteses.
p\left ( x=k \right )=p^{k}\left ( 1-p \right )^{1-k} para k=\left [ 1,0 \right ]
Se p\left ( x=0 \right )=p^{0}\left ( 1-p \right )^{1-0}=\left ( 1-p \right )
Se p\left ( x=1 \right )=p^{1}\left ( 1-p \right )^{1-1}=p
Podemos em fim calcular usando a função de verossimilhança, com base em Bernoulli.
L\left ( \theta \right )=\prod_{i=1}^{n}p^{y_{i}}\left ( 1-p \right )^{1-y_{i}}
Agora o que temos que fazer é maximizar essa função de verossimilhança, da forma que possa ajustar a curva aos dados. Esse é um método de inferência estatística, onde poderemos fazer afirmações a partir de um conjunto de valores representativo sobre uma amostra.
E para resolver o produtório, vamos utilizar logaritmos.
p=\widehat{y}
log L\left ( \theta \right )=\sum_{i=1}^{n}y_{i}log\left ( \widehat{y} \right )+\left ( 1-y_{i} \right )log\left ( 1-\widehat{y} \right )
-log L\left ( \theta \right ) Cross entropy
y_{i}log\left ( \widehat{y} \right )+\left ( 1-y_{i} \right )log\left ( 1-\widehat{y} \right ) Cost function
Conseguimos calcular o Cost Function. Ela representa o objetivo de otimização, ou seja, criamos uma função de custo e a minimizamos para podermos desenvolver um modelo preciso com erro mínimo. Agora o algoritmo usará um método numérico como o Newton-Raphson, iterando até encontrar o menor custo.
Vamos treinar o modelo.
In [14]:
model = LogisticRegression()
model.fit(X_train, y_train)
importance = model.coef_[0
Precisamos tentar prever os valores para os dados não treinados (X_teste), testar o nosso modelo, e é quando a função predict() entra em cena.
In [15]:
y_pred = model.predict(X_test)Uma das principais maneiras de verificar o desempenho do algoritmo é por meio da Matriz de Confusão. Para cada classe, ela informa quais os valores reais (True label) e os valores previstos pelo modelo (predicted label).
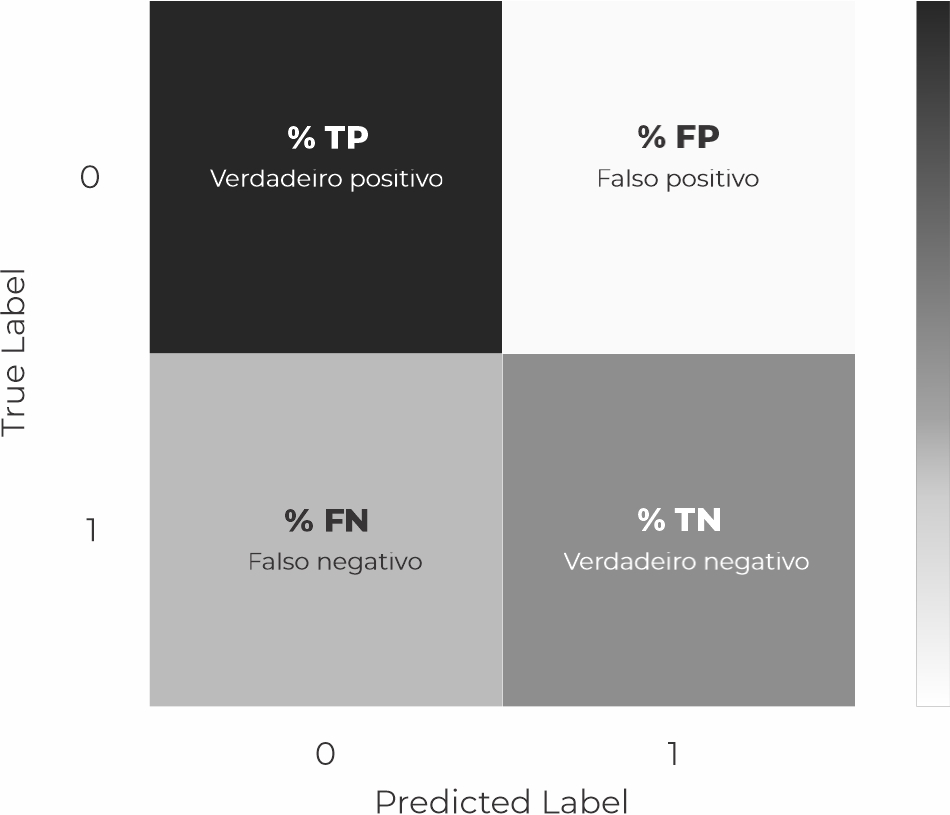
Esse é o modelo da matriz de confusão, ele deixa claro o percentual de cada análise e erros. Assim conseguimos identificar qual o percentual de acerto que o nosso modelo teve na hora de detectar as fraudes, essa métrica é mais relevante, mas claro, não é só isso, precisamos analisar outras métricas para tirar uma conclusão mais precisa.
Definitivamente, é a métrica mais intuitiva e fácil para se entender. A acurácia mostra diretamente a porcentagem de acertos do nosso modelo.
A=\frac{PrevisoesCorretas}{PrevisoesTotais}
Apesar de ser muito direta e intuitiva, a acurácia não é uma boa métrica quando você lida, por exemplo, com dados desbalanceados.
A precisão diz respeito à quantidade (proporcional) de identificações positivas feita corretamente, e é obtida pela equação.
Precision=\frac{TP}{TP+FP}
Mostra a proporção de positivos encontrados corretamente. Matematicamente, você calcula o recall da seguinte maneira:
Rcall=\frac{TP}{TP+FN}
É a média harmônica entre precisão e recall. O melhor valor possível para 0 F1-score é 1 e o pior é 0. É calculado por.
F1-score=2\frac{Precision*Recall}{Precision +Recall}
É a área sob a curva característica de Operação do Receptor. Resumindo é uma curva de probabilidade que representa o grau ou medida de separabilidade, ou seja, quanto maior o AUC, melhor é o desempenho do modelo em distinguir fraudes e não fraudes.
Para gerar o relatório de classificação juntamente com a matriz de confusão, faremos o seguinte código.
In [16]:
# plotar a matrix de confusão
skplt.metrics.plot_confusion_matrix(y_test, y_pred, normalize=True, cmap='BuPu')
sns.despine(left=True, bottom=True)
# imprimir relatório de classificação
print("Relatório de Classificação:\n", classification_report(y_test, y_pred, digits=4))
# imprimir a área sob da curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred)))
Out [16]:
Relatório de Classificação:
Precision recall f1-score support
0 0.9994 0.9998 0.9996 71083
1 0.8172 0.6387 0.7170 119
accuracy 0.9992 71202
macro avg 0.9083 0.8192 0.8583 71202
weighted avg 0.9991 0.9992 0.9991 71202
AUC: 0.8192
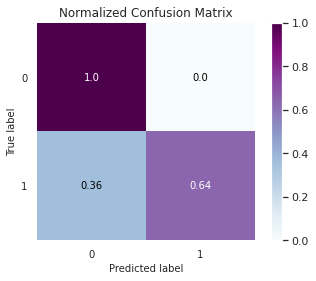
Já percebemos que mesmo o nosso modelo dando uma acurácia bem alta, ele não foi eficaz em detectar as fraudes, conseguiu acertar apenas 64% delas. E um dos motivos, é que treinamos o nosso modelo com dados desbalanceados. Sendo assim, precisamos explorar métodos de balanceamento e ver se irá melhorar o desempenho do nosso modelo.
A classe desbalanceada ocorre quando temos um dataset que possui muitos exemplos de uma classe e poucos exemplos da outra classe.
Essa tendência no conjunto de dados de treinamento pode influenciar muitos algoritmos de aprendizado de máquina, levando a ignorar completamente a classe minoritária, sendo um problema, pois normalmente é a classe minoritária em que as previsões são mais importantes.
Para isso levantamos 4 modelos de balanceamento de classe:
Para cada uma iremos além de balancear, treinar o modelo utilizando a regressão logística e verificar o desempenho observando a matriz de confusão e as outras métricas.
As técnicas de subamostragem ou Random Undersampling removem os dados aleatórios do conjunto de dados de treinamento que pertencem à classe majoritária (classe 0) para equilibrar melhor a distribuição da classe.
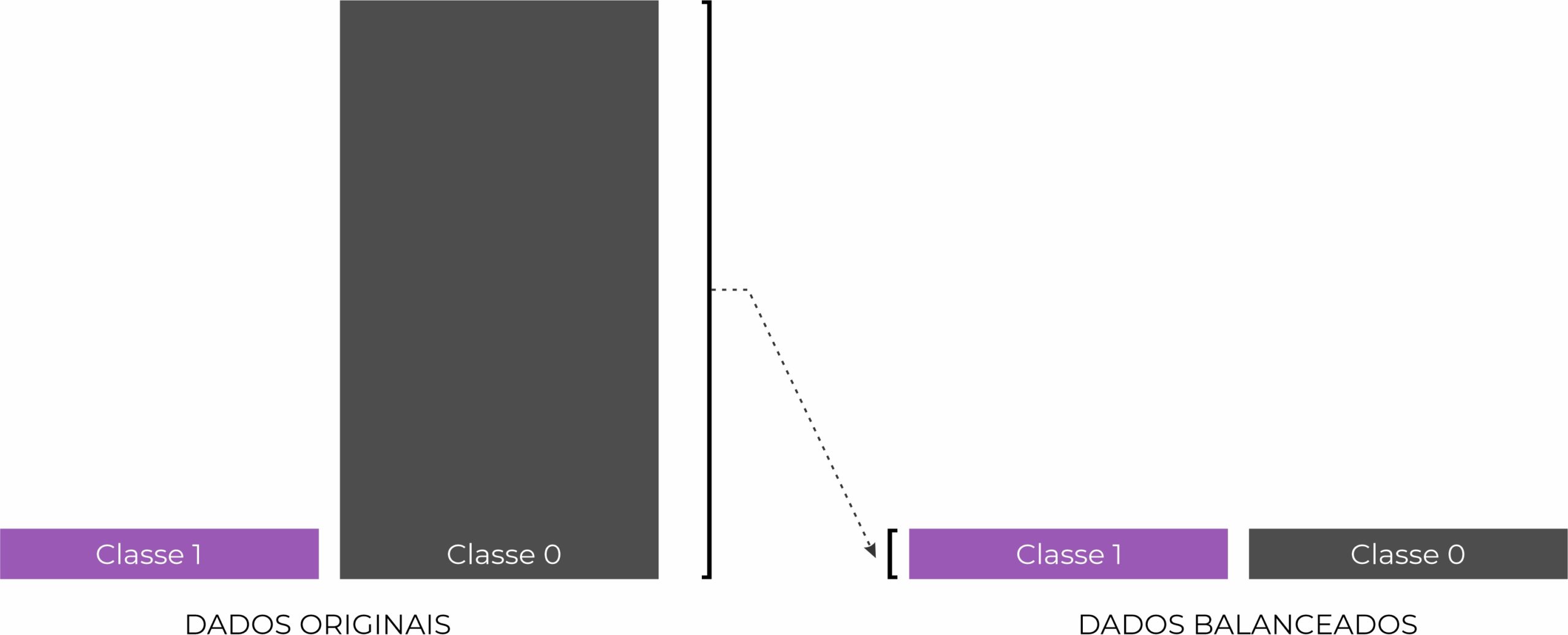
Vamos importar o módulo do RUS, separar os dados de treino e checar à distribuição após o balanceamento.
In [17]:
#RUS (Random Under Sampling)
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler()
X_rus, y_rus = rus.fit_resample(X_train, y_train)
# Checar o balanceamento das classes
print(pd.Series(y_rus).value_counts())
# Plotar a nova distribuição de Classes
flatui = ["#9b59b6", "#b3b3b3"]
sns.set_palette(flatui)
sns.countplot(y_rus);
sns.despine(left=True)
plt.show()
Out [17]:
1 373
0 373
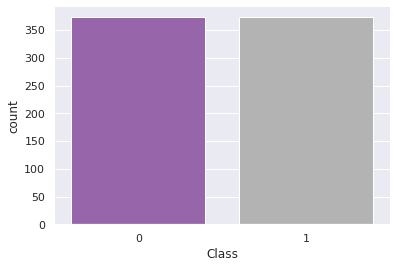
Ele fez o balanço, definindo as fraudes como a classe minoritária, e assim reduzindo os dados das transações normais. Agora vamos treinar o modelo e verificar o seu desempenho.
In [18]:
#modelo de regressão logística
model = LogisticRegression()
model.fit(X_rus, y_rus)
importance_rus = model.coef_[0]
# fazer as previsões em cima dos dados de teste
y_pred_rus = model.predict(X_test)
# plotar a matrix de confusão
skplt.metrics.plot_confusion_matrix(y_test, y_pred_rus, normalize=True, cmap='BuPu')
sns.despine(left=True, bottom=True)
# imprimir relatório de classificação
print("Relatório de Classificação:\n", classification_report(y_test, y_pred_rus, digits=4))
# imprimir a área sob da curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred_rus)))
Out [18]:
Relatório de Classificação:
Precision recall f1-score support
0 0.9998 0.9681 0.9837 71083
1 0.0443 0.8824 0.0844 119
accuracy 0.9680 71202
macro avg 0.5221 0.9252 0.5340 71202
weighted avg 0.9982 0.9680 0.9822 71202
AUC: 0.9252
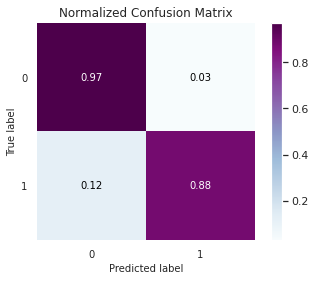
Comparando com o modelo desbalanceado, tivemos uma redução na acurácia global, mas aumentou bastante a assertividade na detecção de fraudes (88%) e reduziu o percentual de falsos negativos.
Synthetic Minority Oversampling Technique ou Técnica de sobreamostragem de minoria sintética é a abordagem mais simples e envolve a duplicação de exemplos na classe minoritária, embora esses exemplos não adiciona nenhuma informação nova ao modelo, esses novos exemplos podem ser sintetizados a partir dos exemplos existentes.
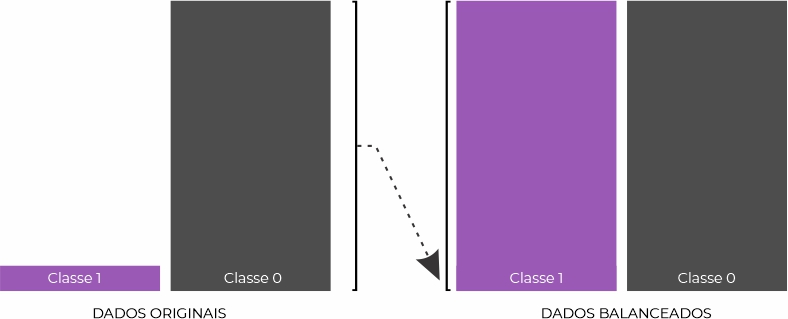
Seguindo o mesmo processo da linha de código da técnica anterior, vamos analisar o balanceamento.
In [19]:
# Balanceamento dos Dados com Over-Sampling (SMOTE)
from imblearn.over_sampling import SMOTE
smo = SMOTE()
X_smo, y_smo = smo.fit_resample(X_train, y_train)
# Checar o balanceamento das classes
print(pd.Series(y_smo).value_counts())
# Plotar a nova distribuição de Classes
flatui = ["#9b59b6", "#b3b3b3"]
sns.set_palette(flatui)
sns.countplot(y_smo);
sns.despine(left=True)
Out [19]:
1 213232
0 213232
Como é possível notar tivemos um aumento no volume de dados que são fraudes. agora vamos avaliar a eficiência do modelo.
In [20]:
#modelo de regressão logistica
model = LogisticRegression()
model.fit(X_smo, y_smo)
importance_smo = model.coef_[0]
# fazer as previsões em cima dos dados de teste
y_pred_smo = model.predict(X_test)
# plotar a matrix de confusão
skplt.metrics.plot_confusion_matrix(y_test, y_pred_smo, normalize=True, cmap='BuPu')
sns.despine(left=True, bottom=True)
# imprimir relatório de classificação
print("Relatório de Classificação:\n", classification_report(y_test, y_pred_smo, digits=4))
# imprimir a área sob da curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred_smo)))
Out [20]:
Relatório de Classificação:
Precision recall f1-score support
0 0.9998 0.9761 0.9878 71083
1 0.0577 0.8739 0.1083 119
accuracy 0.9760 71202
macro avg 0.5288 0.9252 0.5481 71202
weighted avg 0.9982 0.9760 0.9863 71202
AUC: 0.9250
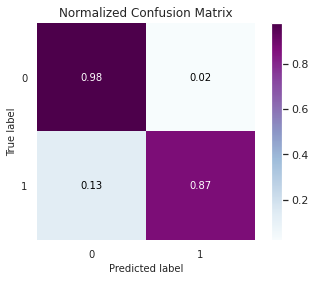
Comparando novamente com o modelo desbalanceado a acurácia foi menor, mas teve maior eficiência na detecção de fraudes (87%).
ADASYN (Abordagem de amostragem sintética adaptável para aprendizado desequilibrado), ele é um método muito semelhante ao Smote, mas depois de criar a amostra, ele adiciona valores aleatórios pequenos aos pontos, tornando-os mais realistas. Em outras palavras, em vez de toda a amostra ser linearmente correlacionada à origem, eles têm um pouco mais de variância, ou seja, elas são dispersas.
In [21]:
from imblearn.over_sampling import ADASYN
ada = ADASYN()
X_ada, y_ada = ada.fit_resample(X_train, y_train)
# Checar o balanceamento das classes
print(pd.Series(y_ada).value_counts())
# Plotar a nova distribuição de Classes
flatui = ["#9b59b6", "#b3b3b3"]
sns.set_palette(flatui)
sns.countplot(y_ada);
sns.despine(left=True)
Out [21]:
1 213232
0 213229
A quantidade de valores de cada classe é muito semelhante ao SMOTE, temos que analisar se essas pequenas diferenças irão alterar no desempenho do modelo.
In [22]:
#modelo de regressão logistica
model = LogisticRegression()
model.fit(X_ada, y_ada)
importance_ada = model.coef_[0]
# fazer as previsões em cima dos dados de teste
y_pred_ada = model.predict(X_test)
# plotar a matrix de confusão
skplt.metrics.plot_confusion_matrix(y_test, y_pred_ada, normalize=True, cmap='BuPu')
sns.despine(left=True, bottom=True)
# imprimir relatório de classificação
print("Relatório de Classificação:\n", classification_report(y_test, y_pred_ada, digits=4))
# imprimir a área sob da curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred_ada)))
Out [22]:
Relatório de Classificação:
Precision recall f1-score support
0 0.9999 0.9178 0.9571 71083
1 0.0185 0.9244 0.0362 119
accuracy 0.9178 71202
macro avg 0.5092 0.9211 0.4966 71202
weighted avg 0.9982 0.9178 0.9555 71202
AUC: 0.9211
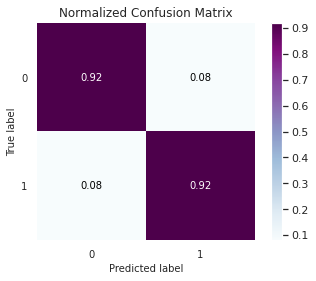
Quando comparamos com o modelo desbalanceado e ao SMOTE, notamos que a acurácia é menor, mas é maior a eficiência em detectar fraudes. Ou seja, pequenas inserções de valores aleatórios fez o modelo ter um bom ganho de desempenho.
O algoritmo é semelhante ao RUS, a diferença é que ele observa a distribuição de classes e elimina aleatoriamente amostras da classe majoritária. Quando dois pontos pertencentes a classes diferentes estão muito próximos um do outro na distribuição, esse algoritmo elimina o ponto de dados da classe majoritária, tentando equilibrar a distribuição.
In [23]:
from imblearn.under_sampling import NearMiss
nr = NearMiss()
X_nr, y_nr = nr.fit_resample(X_train, y_train)
# Checar o balanceamento das classes
print(pd.Series(y_nr).value_counts())
# Plotar a nova distribuição de Classes
flatui = ["#9b59b6", "#b3b3b3"]
sns.set_palette(flatui)
sns.countplot(y_nr);
sns.despine(left=True)
Out [23]:
1 373
0 373
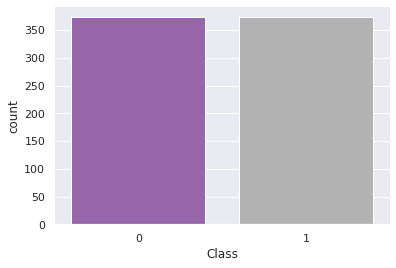
A quantidade de amostra é igual ao modelo do RUS, vamos analisar o desempenho do modelo.
In [24]:
#modelo de regressão logistica
model = LogisticRegression()
model.fit(X_nr, y_nr)
importance_nr = model.coef_[0]
# fazer as previsões em cima dos dados de teste
y_pred_nr = model.predict(X_test)
# plotar a matrix de confusão
skplt.metrics.plot_confusion_matrix(y_test, y_pred_nr, normalize=True, cmap='BuPu')
sns.despine(left=True, bottom=True)
# imprimir relatório de classificação
print("Relatório de Classificação:\n", classification_report(y_test, y_pred_nr, digits=4))
# imprimir a área sob da curva
print("AUC: {:.4f}\n".format(roc_auc_score(y_test, y_pred_nr)))
Out [24]:
Relatório de Classificação:
Precision recall f1-score support
0 0.9997 0.5563 0.7148 71083
1 0.0034 0.9160 0.0069 119
accuracy 0.5569 71202
macro avg 0.5016 0.7361 0.3608 71202
weighted avg 0.9981 0.5569 0.7136 71202
AUC: 0.7361
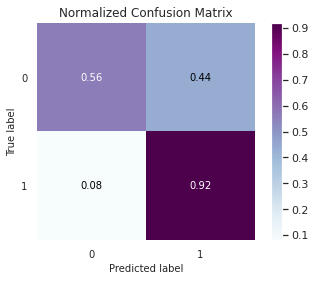
De todos os modelos esse é o que tem a menor acurácia, apesar de ter uma grande eficiência em detectar fraudes (92%), ele falhou bastante em detectar falsos positivos.
É admissível dizer que o balanceamento dos dados é um fator extremamente relevante no contexto de ter uma Machine Learning eficiente, mesmo sua acurácia sendo menor, os modelos balanceados demonstram uma maior eficiência na detecção de fraudes.
O modelo NearMiss, apesar de possuir uma eficiência boa em detectar fraudes, pecou com os falsos positivos (44%).
O RUS teve seu desempenho muito melhor que seu companheiro de modelo NearMiss, tendo uma eficiência de 88% na detecção de fraudes, mas mesmo assim falhou com os falsos negativos (12%).
O ADASYN e o SMOTE foram os dois melhores modelos, com desempenho ótimos, dando ênfase ao SMOTE, que teve uma acurácia de 97,6%, com uma eficiência de 87% na hora de detectar fraudes.
Avaliando o contexto geral, ele é o modelo que escolheríamos para desenvolver nosso sistema de detecção de fraudes, mas antes de terminar nossa análise, um fator importante é entender quais as variáveis que mais influenciam no desempenho dos nossos modelos.
Para isso vamos plotar uma matriz de correlação para cada um dos nossos modelos.
In [25]:
# plotar a matriz de correlação
corr = X_train.corr()
corr_rus = pd.DataFrame(X_rus).corr()
corr_smo = pd.DataFrame(X_smo).corr()
corr_ada = pd.DataFrame(X_ada).corr()
corr_nr = pd.DataFrame(X_nr).corr()
fig, ax = plt.subplots(nrows=1, ncols=5, figsize = (30,8))
fig.suptitle('Matriz de Correlação')
sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=.1, cmap="BuPu", ax=ax[0], mask=np.triu(corr))
ax[0].set_title('Desbalanceado')
sns.heatmap(corr_rus, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=.1, cmap="BuPu", ax=ax[1], mask=np.triu(corr_rus))
ax[1].set_title('Balanceado com RUS')
sns.heatmap(corr_smo, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=.1, cmap="BuPu", ax=ax[2], mask=np.triu(corr_smo))
ax[2].set_title('Balanceado com SMOTE')
sns.heatmap(corr_ada, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=.1, cmap="BuPu", ax=ax[3], mask=np.triu(corr_ada))
ax[3].set_title('Balanceado com ADASYN')
sns.heatmap(corr_nr, xticklabels=corr.columns, yticklabels=corr.columns,
linewidths=.1, cmap="BuPu", ax=ax[4], mask=np.triu(corr_nr))
ax[4].set_title('Balanceado com NearMiss')
plt.tight_layout()
Out [25]:
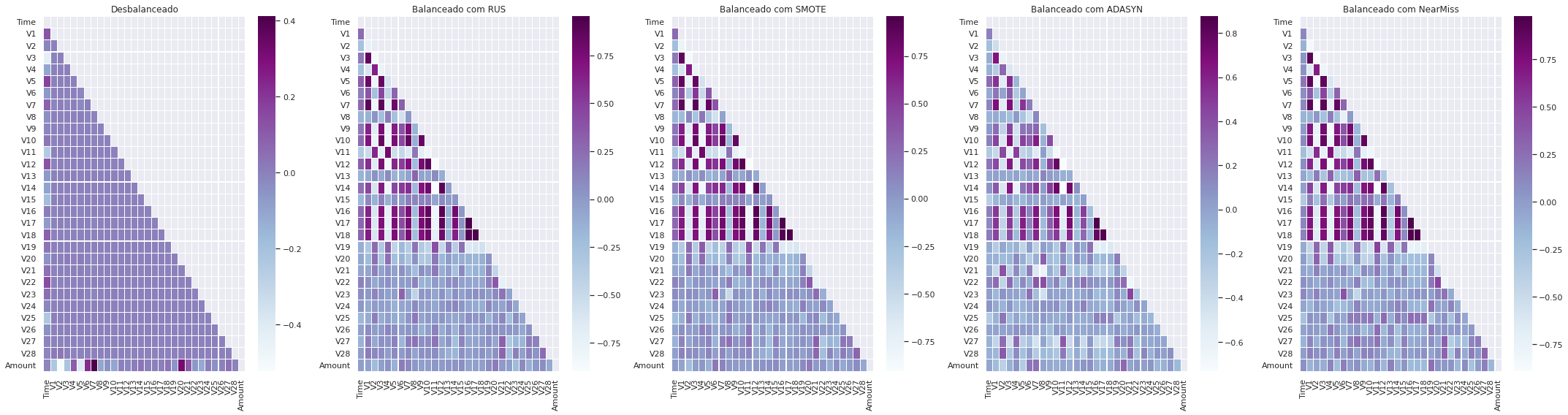
Conseguimos agora ver quais as variáveis se correlacionam proporcional e inversamente. Mas para compreender a influência de cada variável no desempenho do modelo, precisamos explorar os conceitos de coeficientes.
Os modelos de regressão logística são instanciados e se ajustam da mesma forma utilizando o atributo coef_ que contém os coeficientes encontrados para cada variável de entrada. Esses coeficientes podem fornecer a base para uma pontuação bruta de importância do recurso.
Para isso vamos buscar no nosso modelo o coef[1] do nosso melhor modelo (SMOTE), já coletado e assim gerar um plot com as variáveis mais importantes.
In [26]:
importances = pd.Series(data=importance_smo, index=X.columns.values)
importances = importances.sort_values(ascending=False)
plt.figure(figsize=(12,8))
ax = sns.barplot(x=importances, y=importances.index, orient='h', color='#9b59b6')
ax.set_title('Importância de cada feature')
Out [26]:
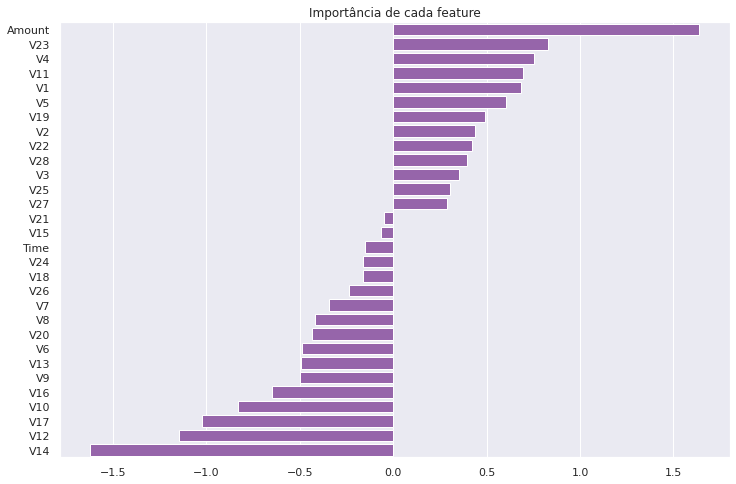
Este é um problema de classificação com classes 0 e 1. Observe que os coeficientes são positivos e negativos. As pontuações positivas indicam uma característica que prevê a classe 1, enquanto as pontuações negativas indicam uma característica que prevê a classe 0.
E analisando nosso gráfico, notamos que a variável Amount, é a que mais impacta na detecção de fraudes, já o V14 é a mais importante para predizer as transações normais.
Desenvolver um modelo de Machine Learning realmente não é fácil, ele possui algumas complexidades na qual é necessário explorar para identificar pontos que prejudicaram o desenvolvimento do modelo, como o caso do balanceamento dos dados e a transformação PCA.
O que esse trabalho impacta para quem trabalha com marketing?
Muita coisa meu caro. Comercial e marketing andam lado a lado, e negócios como e-commerces recebem compras diariamente, imagine essa Machine Learning, ela poderia tornar-se um produto para eles, em que facilitaria a identificação de compras com cartões de créditos fraudados e evitaria complicações para seus clientes, se tornando um diferencial da sua marca.
Sei que foi uma caminhada longa nesse artigo, mas esse é o trabalho de quem vê o mundo através dos dados e assim gera inteligência com uma base forte. Então, meu caro marketeiro.
Prontos para começar do zero?
Arquivo Completo no Github

Oi, sou Hyan e aqui você vai encontrar tudo sobre marketing e tecnologia, assuntos esses na qual eu me dedico a aprender e me desafiar todas as manhãs.
Machine learning • Cartão de crédito • PCA • Sklearn • Fraudes • Transação • Balanceamento • Regressão logística • Matriz de confusão • Acurácia • SMOTE • Comparativo • Transformação
Produção: Zero.ai
Texto: Hyan Dias Tavares
Revisão: Rafael Duarte
Ilustração: Hyan Dias Tavares
Inspiração: Sigmoidal

Hyan Dias | zeroAI
Conta comercial
Olá, como posso te ajudar? Me informe seu nome, email e telefone para iniciarmos uma conversa :)
Deixe seu comentário