zona_sul = ['Botafogo', 'Catete', 'Copacabana', 'Cosme Velho', 'Flamengo', 'Gávea', 'Glória', 'Humaitá', 'Ipanema','Jardim Botânico', 'Lagoa', 'Laranjeiras', 'Leblon', 'Leme', 'São Conrado', 'Urca', 'Vidigal', 'Rocinha']
zona_norte = ['Alto da Boa Vista', 'Andaraí', 'Grajaú', 'Maracanã', 'Praça da Bandeira', 'Tijuca', 'Vila Isabel', 'Água Santa', 'Cachambi', 'Del Castilho', 'Encantado', 'Engenho de Dentro', 'Engenho Novo',
'Higienópolis', 'Jacaré', 'Jacarezinho', 'Lins de Vasconcelos', 'Manguinhos', 'Maria da Graça', 'Méier', 'Piedade', 'Pilares', 'Riachuelo', 'Rocha', 'Sampaio', 'São Francisco Xavier', 'Todos os Santos',
'Bonsucesso', 'Bancários', 'Cacuia', 'Cidade Universitária', 'Cocotá', 'Galeão', 'Jardim Carioca', 'Jardim Guanabara', 'Maré', 'Moneró', 'Olaria', 'Pitangueiras', 'Portuguesa', 'Praia da Bandeira',
'Ramos', 'Ribeira', 'Tauá', 'Zumbi', 'Acari', 'Anchieta','Barros Filho', 'Bento Ribeiro', 'Brás de Pina', 'Campinho', 'Cavalcanti', 'Cascadura', 'Coelho Neto', 'Colégio', 'Complexo do Alemão', 'Cordovil',
'Costa Barros', 'Engenheiro Leal', 'Engenho da Rainha', 'Guadalupe', 'Honório Gurgel', 'Inhaúma', 'Irajá', 'Jardim América', 'Madureira', 'Marechal Hermes', 'Oswaldo Cruz', 'Parada de Lucas', 'Parque Anchieta',
'Parque Colúmbia', 'Pavuna', 'Penha', 'Penha Circular', 'Quintino Bocaiuva', 'Ricardo de Albuquerque', 'Rocha Miranda', 'Tomás Coelho', 'Turiaçu', 'Vaz Lobo', 'Vicente de Carvalho', 'Vigário Geral',
'Vila da Penha', 'Vila Kosmos', 'Vista Alegre', 'Freguesia (Ilha)']
zona_oeste = ['Anil', 'Barra da Tijuca', 'Camorim', 'Cidade de Deus', 'Curicica', 'Freguesia (Jacarepaguá)', 'Gardênia Azul', 'Grumari', 'Itanhangá', 'Jacarepaguá', 'Joá', 'Praça Seca', 'Pechincha', 'Rio das Pedras',
'Recreio dos Bandeirantes', 'Tanque', 'Taquara', 'Vargem Grande', 'Vargem Pequena', 'Vila Valqueire', 'Jardim Sulacap','Bangu', 'Campo dos Afonsos', 'Deodoro', 'Gericinó', 'Jabour', 'Magalhães Bastos',
'Padre Miguel', 'Realengo', 'Santíssimo', 'Senador Camará', 'Vila Kennedy', 'Vila Militar','Barra de Guaratiba', 'Campo Grande', 'Cosmos', 'Guaratiba', 'Inhoaíba', 'Paciência', 'Pedra de Guaratiba', 'Santa Cruz',
'Senador Vasconcelos', 'Sepetiba']
zona_centro = ['São Cristóvão', 'Benfica', 'Caju', 'Catumbi', 'Centro', 'Cidade Nova', 'Estácio', 'Gamboa', 'Lapa', 'Mangueira', 'Paquetá', 'Rio Comprido', 'Santa Teresa', 'Santo Cristo', 'Saúde', 'Vasco da Gama']
for s in zona_sul:
dfRJ_out.neighbourhood_group = dfRJ_out.neighbourhood_group.mask(dfRJ_out.neighbourhood == s, 'Zona Sul')
for n in zona_norte:
dfRJ_out.neighbourhood_group = dfRJ_out.neighbourhood_group.mask(dfRJ_out.neighbourhood == n, 'Zona Norte')
for o in zona_oeste:
dfRJ_out.neighbourhood_group = dfRJ_out.neighbourhood_group.mask(dfRJ_out.neighbourhood == o, 'Zona Oeste')
for c in zona_centro:
dfRJ_out.neighbourhood_group = dfRJ_out.neighbourhood_group.mask(dfRJ_out.neighbourhood == c, 'Centro')
dfRJ_out.groupby(['neighbourhood_group']).price.mean().sort_values(ascending=False)[:10]




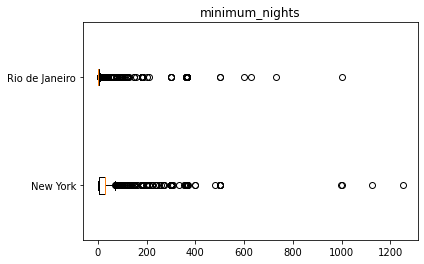
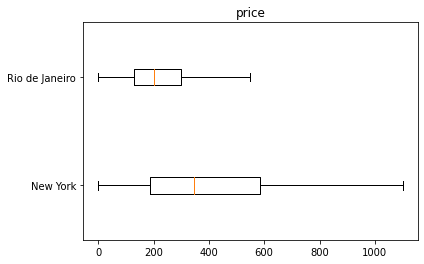
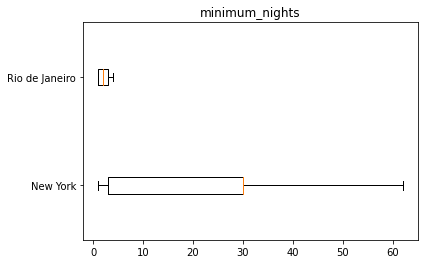
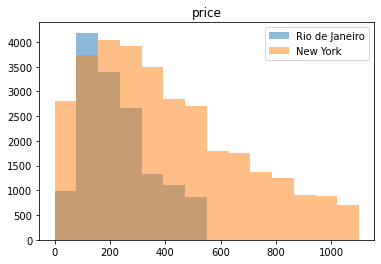
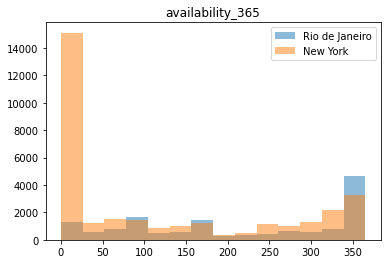
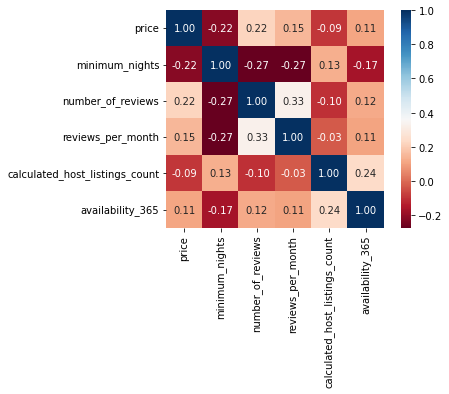
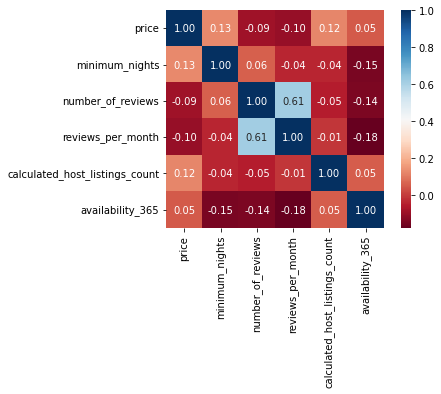
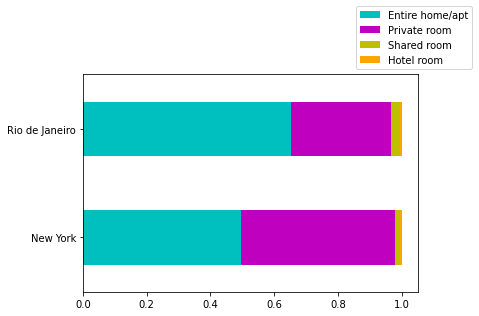
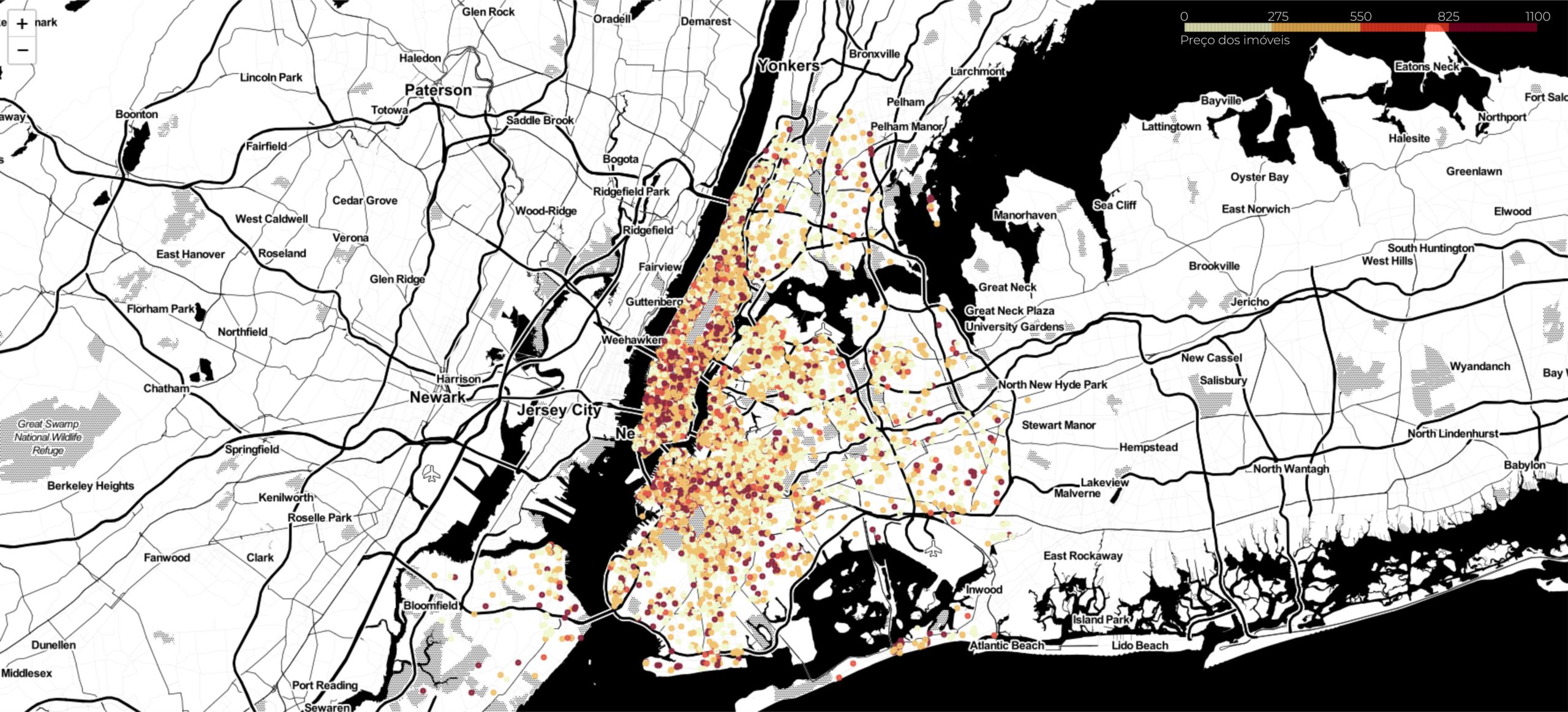
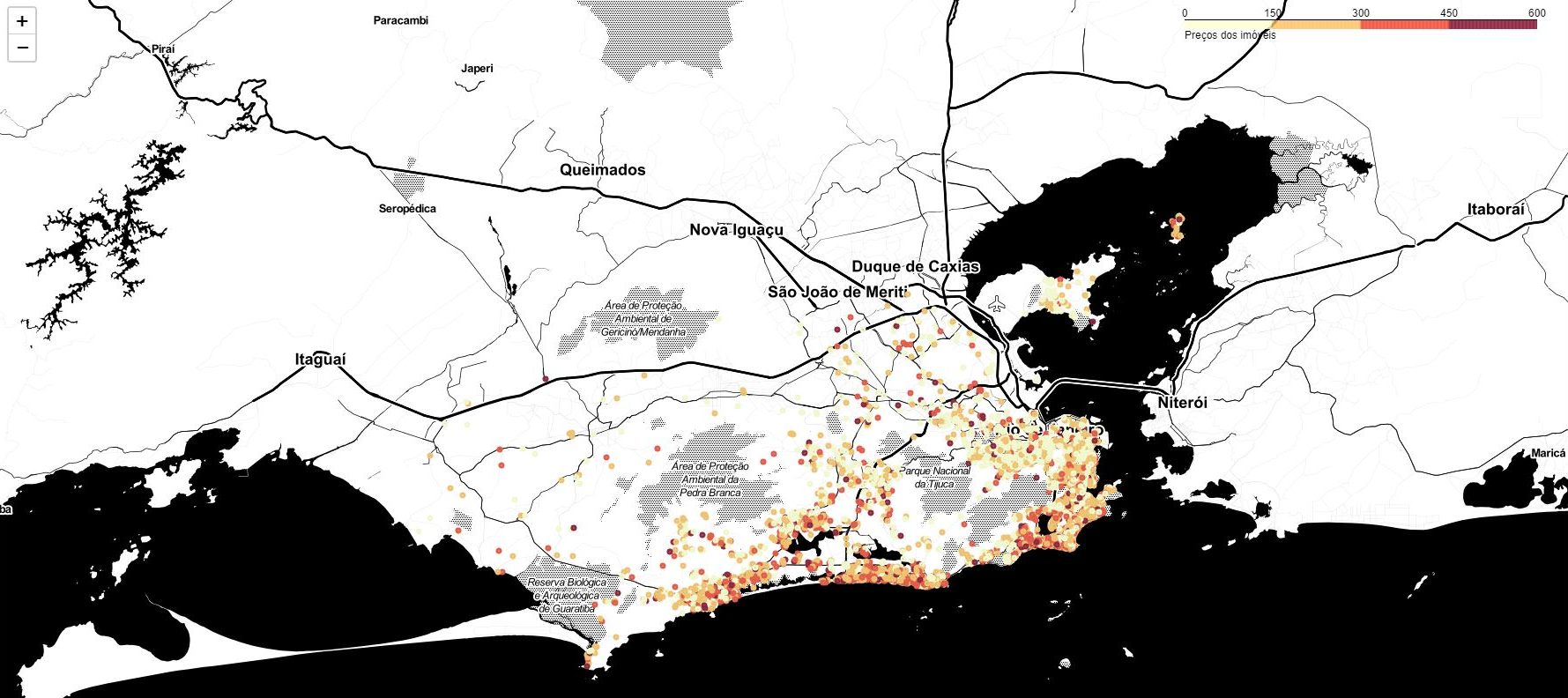






Deixe seu comentário